ARIMA é um dos modelos mais populares para previsão e análise de séries temporais. Sua sigla vem do inglês autoregressive integrated moving average, que representa a combinação de dois outros, AR e MA. É muito utilizado por estatísticos e economistas; nós, engenheiros de machine learning e cientistas de dados, devemos conhecê-lo e usá-lo também, além de ARIMA ser um excelente modelo, esse serve de comparação de acurácia contra modelos mais avançados como redes neurais recorrentes e wavenet.
Para bem funcionar, o modelo ARIMA precisa lidar com séries históricas estacionárias (com média e variância constantes), caso essas não sejam, precisam ser transformadas. Além das transformações, o modelo precisa ter seus parâmetros estimados para melhor ajustarem-se aos dados. O ARIMA clássico possui três parâmetros; a extensão desse, SARIMA, seis. Todas essas etapas consumem tempo.
Para minimizar podes utilizar ferramentas de AutoML, que realizam busca automatizada para otimização dos parâmetros. A AWS possui meios para tal — o Amazon Forecast.
Caso seja necessária uma boa previsão, mas sem grandes detalhes de análise, a ferramenta Forecast pode ajudar. Ela é um sistema de AutoML que treina e faz previsões com uma série de algoritmos. A Amazon utiliza o Forecast internamente para previsão em vendas no varejo e tráfego de web e o disponibilizou ao seus clientes. Neste texto o modelo escolhido é o ARIMA para o contexto de séries temporais de preços de ações.
Este artigo utilizou as ferramentas da AWS, que é um conjunto de serviços em nuvem, para armazenamento dos dados e implementação do modelo e previsão. A série de preços do grupo Ser Educacional foi obtida pelo site Yahoo! Finanças, um arquivo .csv do período de 29/10/2013 a 27/04/2021. Ao longo do texto serão comentadas algumas vantagens e desvantagens do uso do Amazon Forecast.
PREPARAÇÃO DOS DADOS
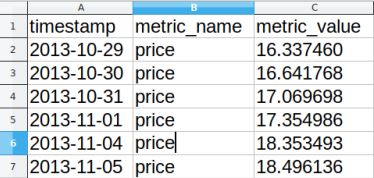
Antes de criar o modelo é preciso e preparar os dados de um modo peculiar (esta é uma desvantagem do Forecast). De posse do arquivo .csv, devem ser excluídas todas as colunas, menos aquelas com datas (“Date”) e preços de fechamento (“Close”), tais colunas precisam ser renomeadas como “timestamp” e “metric_value” – respectivamente. Após isso, uma nova coluna deve ser criada, popula suas linhas com o nome “price”. Esta também deve ser renomeada como “metric_name”. Agora a ordem das colunas deve ser ajustada para “metric_name”, “timestamp”,“metric_value”(A ordem é de menor importância). Tudo pode ser feito através do LibreOffice ou outro editor de textos.
AMAZON S3
Após a preparação dos dados é hora de armazenar o arquivo .csv em nuvem. Os dados coletados foram armazenados no serviço Amazon Simple Storage Service (Amazon S3) da AWS, que, segundo documentação, cria buckets (contêiners) para armazenar arquivos de tamanhos de até 5 TB. Nestes contêineres que a série temporal será alocada para uso.
Usando o AWS Console, após logares em tua conta AWS, indo ao botão “Services” na barra acima, ou na busca por serviços, serão exibidos todos os serviços oferecidos pela AWS.


Ao acessar o serviço S3 é hora de criar um contêiner para guardar o arquivo com a série. Para criá-lo deve-se apertar o botão “Criar Bucket” no lado direito da tela.

Uma nova página será aberta com algumas informações a preencher, a primeira será o nome do bucket, uma informação importante que servirá para criar o link de acesso ao contêiner. As demais informações podem ser deixadas em padrão. Ao final da página há um novo botão com novamente o nome de “Criar Bucket”, ao clicar no nome a ferramenta de armazenamento o objeto está criado.

Parte superior da página de informações do Bucket. O nome deve ser criado.

O passo seguinte é armazenar a série.
Na página anterior haverá agora o contêiner criado, clicando em seu nome uma outra sessão abrir-se-á mostrando o botão para carregamento de arquivos.


O objeto armazenado por padrão não é público, o link que o aponta está criado para leitura dentro da estrutura AWS pelo dono da conta. O link será necessário para acessar os dados na hora da análise.
A criação de contêineres é uma fase rápida, simples e intuitiva. Saber utilizar o S3 é importante para uma séries de serviços em nuvem. Uma boa vantagem a ser destacada.
AMAZON FORECAST
Após os dados preparados e armazenados em AWS S3 (seguindo os passos na sessão anterior). Vá à sessão do Amazon Forecast da barra superior. Em página do Forecast, é preciso agora clicar no botão que verifica os grupos de datasets, pelo botão “View dataset groups”.

Na próxima página, clica no botão “Create dataset group”. Na sessão posterior ao clique, dá um nome ao grupo de conjunto de dados, de preferência um nome que represente os dados em posse para melhor controle. E escolha o domínio da previsão — forecasting domain — “Custom”. Tais domínios são os esquemas de estruturação de dados que AWS fornece, para o caso de séries temporais “Custom” aparentemente uma é boa escolha. E clica em “Next”.
No próximo passo dá um nome ao conjunto de dados e escolha a frequência da sua série. Ações do grupo Ser Educacional coletadas têm os valores diários, então deixa a opção padrão “day”, mas se tua série for de dados anual, e. g., muda para “year”.
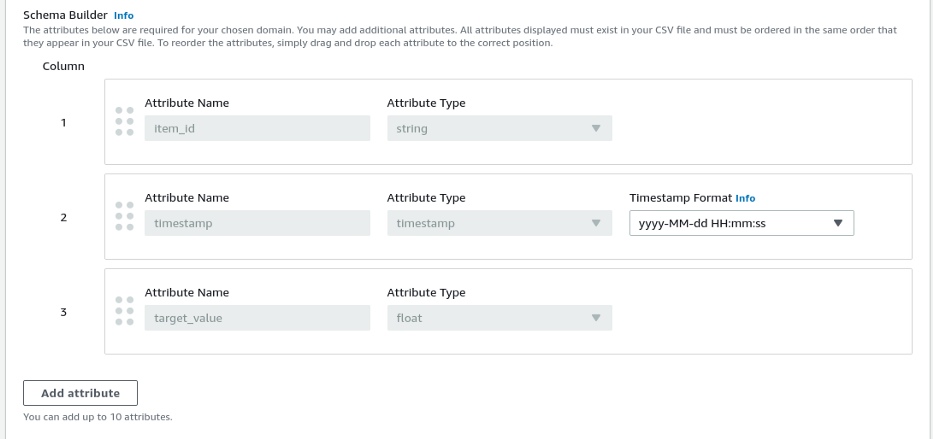
Agora é hora de ajustar o esquema aos dados. Dependendo de como estão posicionadas as colunas de teu csv, muda de lugar as colunas pela parte com nome “Column” arrastando os campos por meio das bolas ao lado desses. Ajusta na coluna “timestamp” o formato, no caso do dataset usado muda-o para o padrão “yyyy-MM-dd”, sem a parte de horas. Não é preciso neste exemplo adicionar mais atributos.
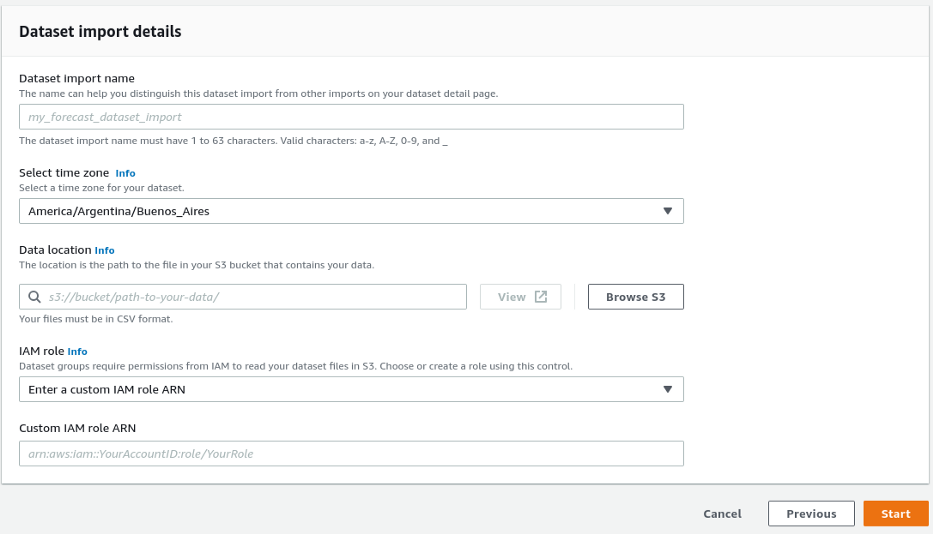
Dá um nome ao dataset para melhor o localizar. É possível usar fuso horário para para série, como os dados são da bolsa de São Paulo, o fuso igual de é America/Argentina/Buenos_Aires (não é obrigado). Na sessão “Browse S3” é onde o arquivo .csv está armazenado, de lá o modelo o usará para o treino. Acessa o local e seleciona o arquivo. Por fim, cria um IAM role, que será um usuário que operará o modelo (uma prática de segurança da AWS). Aperta “Start”.
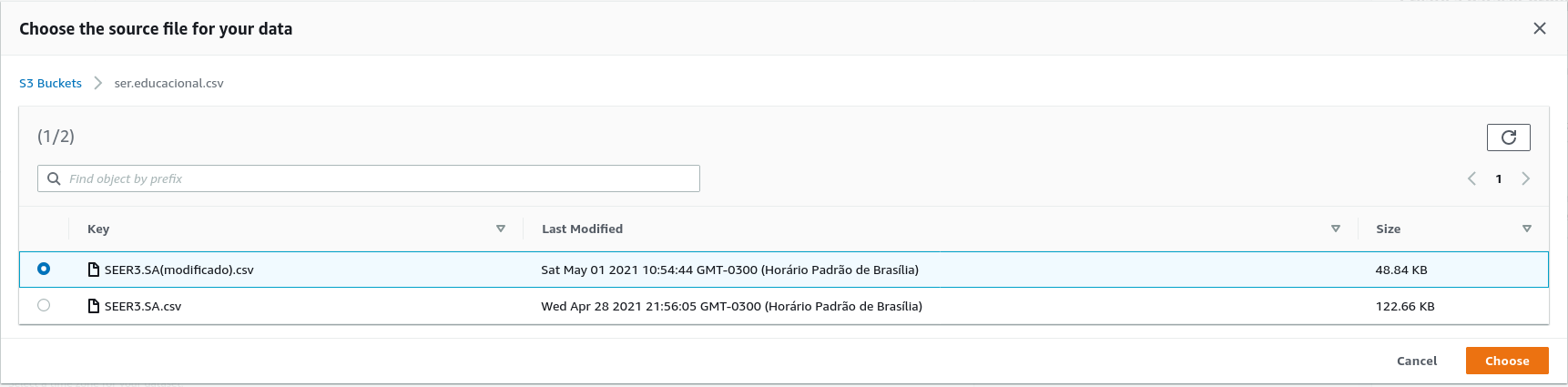
Após essas etapas, que podem levar alguns minutos para serem concluídas (ponto negativo), o conjunto de dados está pronto. Após isso é a fase de construção do modelo.
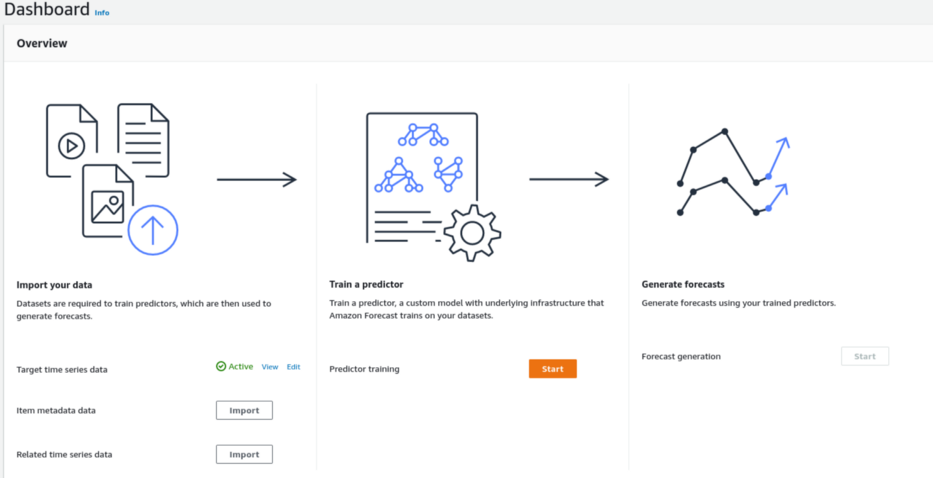
Dá um nome ao modelo (“predictor”), escolha o horizonte de previsão (“Forecasting Horizon”), que é até onde o modelo fará uma previsão (neste experimento foi selecionado valor 15) e seleciona a frequência (aqui diária, “day”).
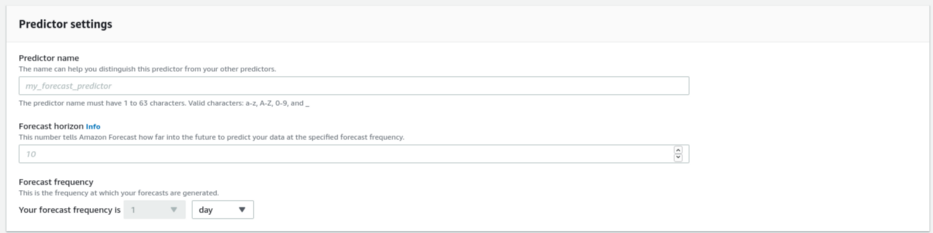
Em “Predictor Details” seleciona a opção “Manual” e “ARIMA”, caso seja deixado como AutoML o AWS Forecast treinará todos os modelos disponíveis e o com melhores métricas será escolhido para as previsões.
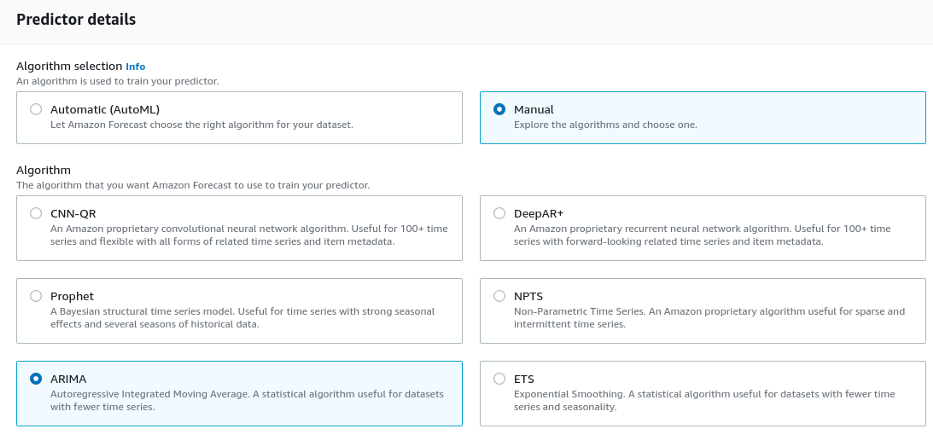
Em “Number of backtest windows” selecionamos a quantidade de vezes que a série é dividida para a validação (backtest é uma espécie de validação cruzada para séries históricas respeitando sequência). Deixaremos como padrão 1, mas é possível dividir até cinco vezes os dados; o tempo de validação aumenta, porém o modelo torna-se mais confiável. Em “Backtest window offset” escolhemos o ponto que os dados são divididos para o backtest, aqui selecionamos 15, pois é necessário ser igual e maior que o valor em “Forecasting Horizon”. O valor de 15 representa as últimas 15 observações que servirão como conjunto de teste.

As outras opões em “Predictor Details” podem ser deixadas como padrão.
Em “Advanced Configurations” serão ajustadas a formas de imputação de dados em falta, a documentação AWS neste ponto é confusa (uma importante desvantagem que presumo será corrigida em breve). Em “Featurization”, há estas chaves e valores com strings: “frontfill”: “none”;“middlefill”: “zero” e “backfill”: “zero”. Substitui os “zeros” em “backfill” e “middlefill” por “median”, “frontfill” deve ser deixado como está. Neste experimento a forma de imputação foi o uso da mediana (median), usar zeros para séries financeiras geralmente não é um boa estratégia, mas fica a critério do leitor testar outras (as mais usadas são o preenchimento com o valor anterior antes do dado em falta ou interpolação do valor anterior e posterior, mas não são, pelo menos ainda, oferecidas).
Nota: Outro detalhe interessante do esquema AWS para a aplicação Forecast é a criação da frequência dos dados, como os dados de ações brasileiras funcionam de segunda à sexta não há, então, registros dos dias de sábado e domingo. Todavia o Forecast cria esses dias, mas com valor NaN. Como foi especificado que o preenchimento dos dados será por mediana, os buracos, e serão muitos, terão o valor daquela.

Também é possível configurar as séries para o caso de feriados, que são dias sem pregão.

Após tudo ajustado, aperta o botão “Start”, o modelo será treinado com melhores parâmetros selecionados. A fase de treino é uma operação custosa e geralmente leva alguns minutos.
Com o modelo ajustado é hora de fazer previsões, volta à tela “Dashbord” e aperta o botão “Start” em “Genetate forecasts”. As previsões também necessitam de nome; no campo “Forecast name”, seleciona o ARIMA no campo “Predictor”. O campo com quantis é opcional. Aperta “Start”.
Volta ao “Dashaboard”. Quando os previsões estiverem prontas clica em “Lookup forecast” ainda em “Generate forecasts”. Esta opção cria gráficos e expõe as estatísticas que avaliam o modelo.
Escolha as previsões criadas a pouco no campo “Forecast” e seleciona os dias de inicio e fim do predito. As datas são baseadas na seleção em “Forecast horizon”, presta atenção aos avisos de erro (se chegarem, aparecerão no topo da tela em vermelho) para datas escolhidas além das capacidades preditivas; chegando erros, modifica as datas. Dois novos campos de preenchimento irão aparecer, “Forecast key” e “value”; neste escreva “price”, naquele selecione “item_id”.
É possível agora avaliar o resultado modelo.
Na sessão “View predictors” em “Dashboard” seleciona o preditor treinado e olha as métricas.

E por fim a análise gráfica mostrando a tendência dos preço:
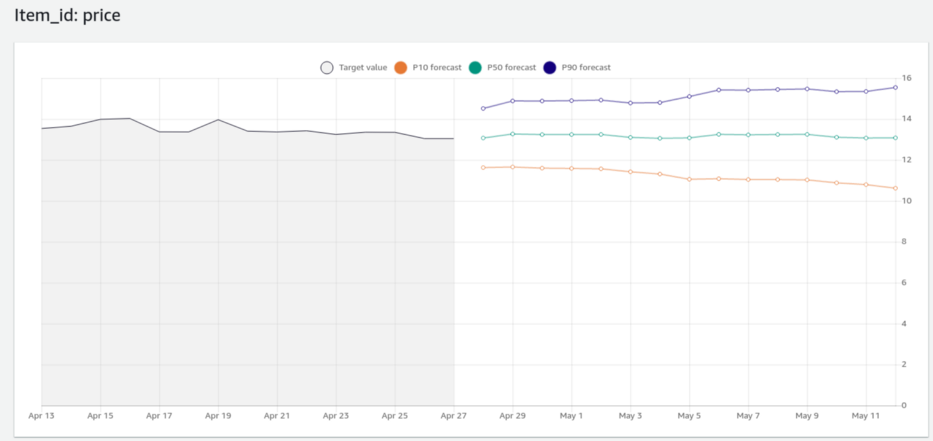
O gráfico é mostra resultados de previsão por meio de quantis, a linha verde representa a mediana dos valores possíveis previstos, como as outras duas o primeiro e nono decis. Podemos interpretar este gráfico dando mais atenção a linha da mediana e tendo em mente que é possível, mas pouco provável, que os valores atinjam os decis.
Ao leitor é deixada a tarefa de testar outras formas de preenchimento de dados faltantes e outros modelos e avaliar os resultados.
O AutoML é uma realidade, num futuro muitíssimo próximo não existirá uma grande preocupação em decorar e buscar muitas linhas de código para selecionar e treinar modelos de aprendizado de máquina. Ao engenheiro de ML são necessárias capacidades analíticas de saber qual e como um modelo deve ser usado, saber limpar e criar gráficos dos dados e extrair desses informações úteis (estas duas tarefas também estão sendo automatizadas), interpretá-las e as usar para o negócio.
O Amazon Forecast possui limitações, mas é útil para sentir como é o mundo do AutoML, ele ainda precisa ser melhorado, sabemos, porém, das grandes capacidades da AWS e é questão de tempo até chegar a um estado aceitável de uso.
